Deciphering Encoder-Decoder Architectures: Unraveling the Magic Behind Question-Answer Systems
In the realm of natural language processing, encoder-decoder architectures have garnered significant attention for their ability to tackle various tasks, including machine translation, text summarization, and question-answering. In this comprehensive exploration, we'll delve into the intricacies of encoder-decoder architectures, offering a deeper understanding of their inner workings and the art of training question-answer systems.
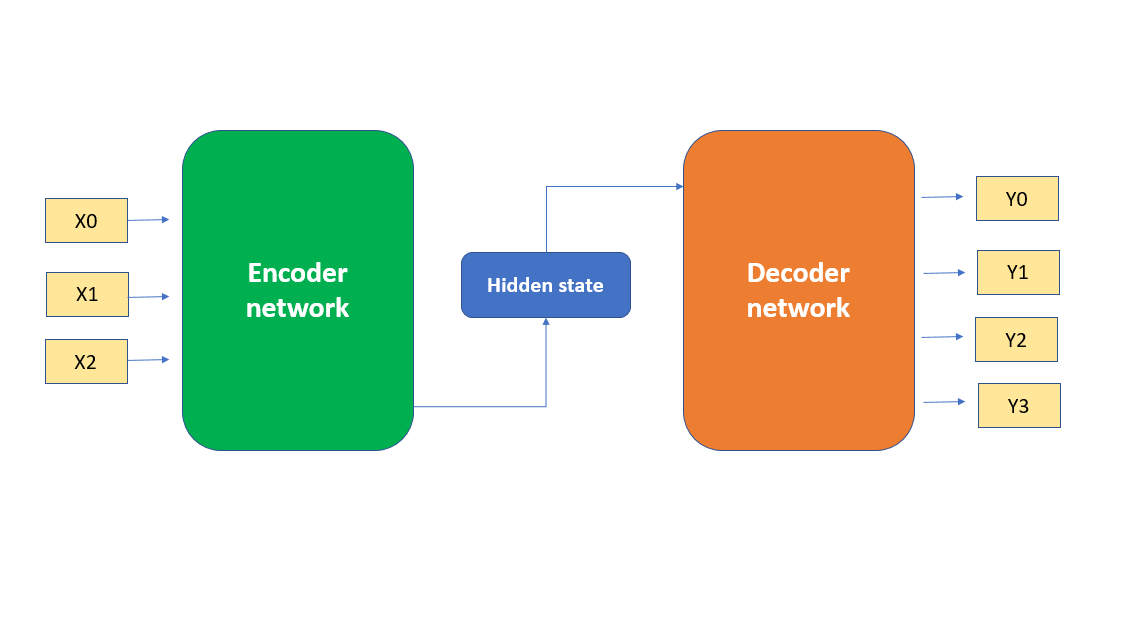
Encoder-decoder architectures, at their core, comprise two essential components: the encoder and the decoder. These components work in tandem to process input sequences and generate corresponding output sequences. The encoder extracts meaningful information from the input, while the decoder utilizes this information to generate outputs.
The Encoder: Unveiling Contextual Understanding
The encoder serves as the foundation of the architecture, imbuing it with the power to comprehend input sequences. It captures the essence of the input by creating a condensed representation known as the context vector. Think of the encoder as a vigilant observer, meticulously analyzing every element of the input sequence to distill its essence into a coherent and concise form.
Intuition Behind Encoder Operation:
Imagine you're reading a book. With each page you turn, you assimilate information and gradually build an understanding of the story. Similarly, the encoder processes the input sequence step-by-step, synthesizing contextual information at each stage. Each token in the input sequence contributes to the evolving narrative, ultimately culminating in the creation of the context vector—a distilled essence that encapsulates the entire input sequence's meaning.
The Decoder: Crafting Responses with Finesse
While the encoder lays the groundwork for understanding, the decoder brings the architecture to life by generating meaningful responses. It leverages the context vector provided by the encoder to craft responses that are contextually relevant and linguistically coherent. Think of the decoder as a skilled storyteller, weaving together words and phrases to craft compelling narratives.
Consider a skilled conversationalist engaging in dialogue. Armed with contextual understanding, they craft responses that resonate with the conversation's flow and tone. Similarly, the decoder utilizes the context vector as a guiding beacon, crafting responses that align with the input's underlying context. With each word it generates, the decoder adds depth and nuance to the unfolding narrative, culminating in a response that mirrors the input's intent and meaning.
Training the Question-Answer System: A Journey of Learning
Training a question-answer system involves imbuing the encoder and decoder with the knowledge and intuition required to understand and respond to queries accurately. It's akin to teaching a budding conversationalist the nuances of language and communication, instilling in them the ability to comprehend queries and formulate coherent responses.
The Training Process: During training, the encoder and decoder learn to collaborate harmoniously, with the encoder distilling the essence of input sequences and the decoder utilizing this distilled essence to craft responses. Through an iterative process of observation and refinement, the model hones its understanding and linguistic prowess, gradually evolving into a proficient conversationalist capable of navigating the complexities of human language.
Training a Question-Answer System: Now, let's walk through the process of training a question-answer system using an encoder-decoder architecture with LSTM networks.
- Data Collection:
- The first step is to collect a dataset of question-answer pairs. This dataset will serve as the training data for our system.
- Tokenization and Embedding:
- Each question and answer in the dataset is tokenized into individual words or subwords.
- The tokens are then converted into numerical representations using word embeddings. Word embeddings capture the semantic meaning of words and allow the model to work with continuous numerical data.
- Encoder:
- The tokenized questions are fed into the encoder LSTM one token at a time.
- The LSTM processes the tokens sequentially, updating its hidden state at each time step.
- Once the entire question is processed, the final hidden state of the encoder serves as the context vector.
- Decoder:
- During training, the context vector from the encoder is passed as the initial hidden state of the decoder LSTM.
- The tokenized answers are fed into the decoder LSTM one token at a time.
- At each time step, the decoder LSTM generates the next word in the answer sequence based on the context vector and the previously generated tokens.
- The model is trained to minimize the discrepancy between its predicted answers and the ground truth answers in the dataset.
- Training Objective:
- The objective of training is to teach the model to generate appropriate answers given input questions.
- This involves jointly training the encoder and decoder components of the model using the question-answer dataset.
- The model's parameters are updated using backpropagation and gradient descent to minimize the loss between the predicted answers and the ground truth answers.
- Evaluation and Inference:
- Once trained, the model can be evaluated on a separate validation set to assess its performance.
- During inference, when the model is used to respond to user queries, the process is similar to training. The question is tokenized, fed into the encoder to obtain the context vector, and then passed to the decoder to generate the response.
Conclusion
In this exploration, we've peeled back the layers of encoder-decoder architectures, shedding light on their inner workings and the art of training question-answer systems. Armed with a deeper understanding of these architectures, we're better equipped to harness their potential and build intelligent systems capable of engaging in meaningful conversations and unlocking new frontiers in natural language processing.
Overview Diagram