MAGIC OF GAN'S
In the realm of artificial intelligence and machine learning, few innovations have sparked as much excitement and creativity as Generative Adversarial Networks (GANs). Introduced by Ian Goodfellow and his colleagues in 2014, GANs have revolutionized the field of generative modeling, enabling the creation of incredibly realistic synthetic data.
In this comprehensive guide, we'll delve into the inner workings of GANs, exploring their key components including the generator, discriminator, latent space, and probability distributions. By the end, you'll have a deep understanding of how GANs work and their profound implications across various domains.
Understanding GANs:
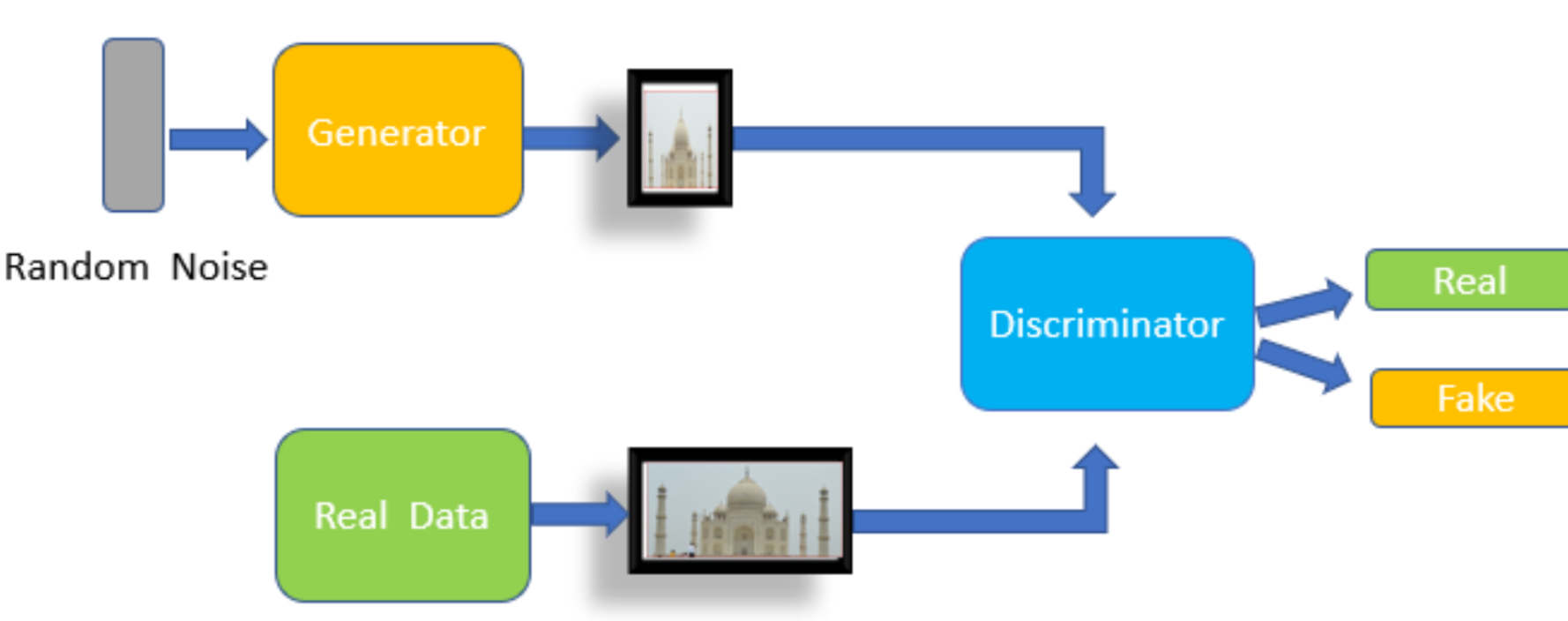
Generative Adversarial Networks (GANs) are a class of machine learning models that consist of two neural networks – the generator and the discriminator – which are pitted against each other in a game-like scenario. The generator aims to produce synthetic data samples that are indistinguishable from real data, while the discriminator tries to differentiate between real and fake samples.
The Generator:
The generator is the creative force behind GANs. It takes random noise as input and transforms it into meaningful data samples. Here's how it works:
- Input Noise: The generator starts with noise vectors sampled from a probability distribution, often Gaussian or uniform.
- Mapping to Data: Through a series of neural network layers, the generator learns to map these noise vectors to points in a high-dimensional space, known as the latent space.
- Generating Samples: The generator then transforms points in the latent space into synthetic data samples, aiming to mimic the distribution of real data.
- Training Objective: The generator's objective is to fool the discriminator into classifying its fake samples as real.
The Discriminator:
The discriminator acts as the adversary to the generator. Its role is to differentiate between real and fake data samples. Here's how it operates:
- Real vs. Fake Classification: The discriminator receives both real data samples from the training set and fake samples generated by the generator.
- Learning to Discriminate: Through training, the discriminator learns to classify whether each sample it receives is real or fake.
- Adversarial Training: As the discriminator becomes more proficient at distinguishing between real and fake samples, it provides feedback to the generator, guiding its improvement.
Latent Space:
The latent space is a crucial concept in GANs. It serves as a high-dimensional representation where the generator learns to map input noise vectors to meaningful data samples. Here's a closer look:
- Definition: Latent space is a conceptual space where each point represents a possible output of the generator.
- Exploration and Manipulation: Researchers can explore and manipulate the latent space to generate new data samples with controlled variations.
- Representation Learning: Learning a meaningful latent space is a form of representation learning, where the GAN captures the underlying structure and features of the data distribution.
Probability Distributions:
Probability distributions play a fundamental role in GANs, both in generating input noise and modeling data distributions. Here's their significance:
- Input Noise Distribution: The generator typically takes noise vectors sampled from a simple probability distribution, such as Gaussian or uniform.
- Data Distribution Modeling: GANs aim to model the underlying data distribution. Through adversarial training, the generator learns to approximate this distribution, generating samples that closely resemble real data.
GANs, despite their remarkable capabilities, do face several challenges:
1. Mode Collapse:
- Issue: Mode collapse occurs when the generator produces limited varieties of samples, ignoring large portions of the data distribution. In extreme cases, the generator might only produce a single output regardless of the input noise.
- Solution: Techniques like minibatch discrimination, diversity-promoting objectives, and architectural changes can mitigate mode collapse.
2. Training Instability:
- Issue: GAN training is notoriously unstable, often leading to oscillations and failure to converge. The generator and discriminator can become stuck in a stalemate, where neither can improve.
- Solution: Strategies such as careful weight initialization, using appropriate activation functions, and adjusting learning rates can help stabilize training.
3. Evaluation Metrics:
- Issue: Evaluating the performance of GANs can be challenging due to the absence of clear metrics. Common metrics like Inception Score and Frechet Inception Distance (FID) have limitations and may not fully capture the quality of generated samples.
- Solution: Developing new evaluation metrics that better correlate with human perception is an active area of research. Additionally, employing human evaluators can provide qualitative feedback on generated samples.
4. Overfitting:
- Issue: GANs are susceptible to overfitting, where the generator memorizes the training data rather than learning its underlying distribution. This can result in poor generalization to unseen data.
- Solution: Regularization techniques such as dropout, weight decay, and augmentation can help prevent overfitting. Additionally, using larger and more diverse datasets can improve generalization.
5. Lack of Robustness:
- Issue: GANs can be sensitive to hyperparameters and small changes in the training process, making them less robust. Different datasets and tasks may require fine-tuning of parameters.
- Solution: Conducting extensive hyperparameter tuning and experimenting with various architectures and training strategies can help achieve better performance. Additionally, techniques like transfer learning can leverage pre-trained models to bootstrap training.
6. Convergence Issues:
- Issue: GAN training may suffer from convergence issues, where the generator and discriminator fail to converge to an equilibrium. This can result in suboptimal performance or unstable training.
- Solution: Techniques such as gradient penalties (e.g., Wasserstein GANs), spectral normalization, and progressive growing can promote stable convergence and improve overall performance.
7. Scalability:
- Issue: GAN training can be computationally intensive and resource-demanding, particularly for high-resolution image generation tasks. Scaling GANs to larger datasets and higher resolutions poses significant challenges.
- Solution: Leveraging distributed training frameworks, optimizing model architectures for efficiency, and utilizing specialized hardware (e.g., GPUs, TPUs) can improve scalability and speed up training.
Addressing these challenges requires a combination of theoretical insights, algorithmic innovations, and empirical experimentation. Despite these hurdles, ongoing research continues to push the boundaries of what GANs can achieve, making them increasingly valuable tools in various domains.
Conclusion
Generative Adversarial Networks (GANs) represent a groundbreaking advancement in generative modeling, offering a powerful framework for creating realistic synthetic data. By harnessing the interplay between the generator and discriminator, GANs unlock the potential for generating diverse and high-quality data across various domains. As research in GANs continues to evolve, their impact on fields such as computer vision, natural language processing, and healthcare is poised to be transformative.