Unveiling the Power of LSTM Networks: A Comprehensive Guide
In the realm of artificial intelligence and deep learning, recurrent neural networks (RNNs) have long been heralded for their ability to process sequential data. However, traditional RNNs often struggle to capture long-term dependencies due to the vanishing gradient problem. This limitation led to the development of a groundbreaking solution: the Long Short-Term Memory (LSTM) network. In this guide, we'll delve into the architecture, purpose, and key components of LSTM networks, shedding light on their remarkable capabilities.
Understanding LSTM Networks
LSTM networks are a type of recurrent neural network architecture specifically designed to overcome the limitations of traditional RNNs in capturing long-term dependencies. They excel in processing and making predictions based on sequential data, such as time series, text, audio, and more.
Architecture of LSTM Networks
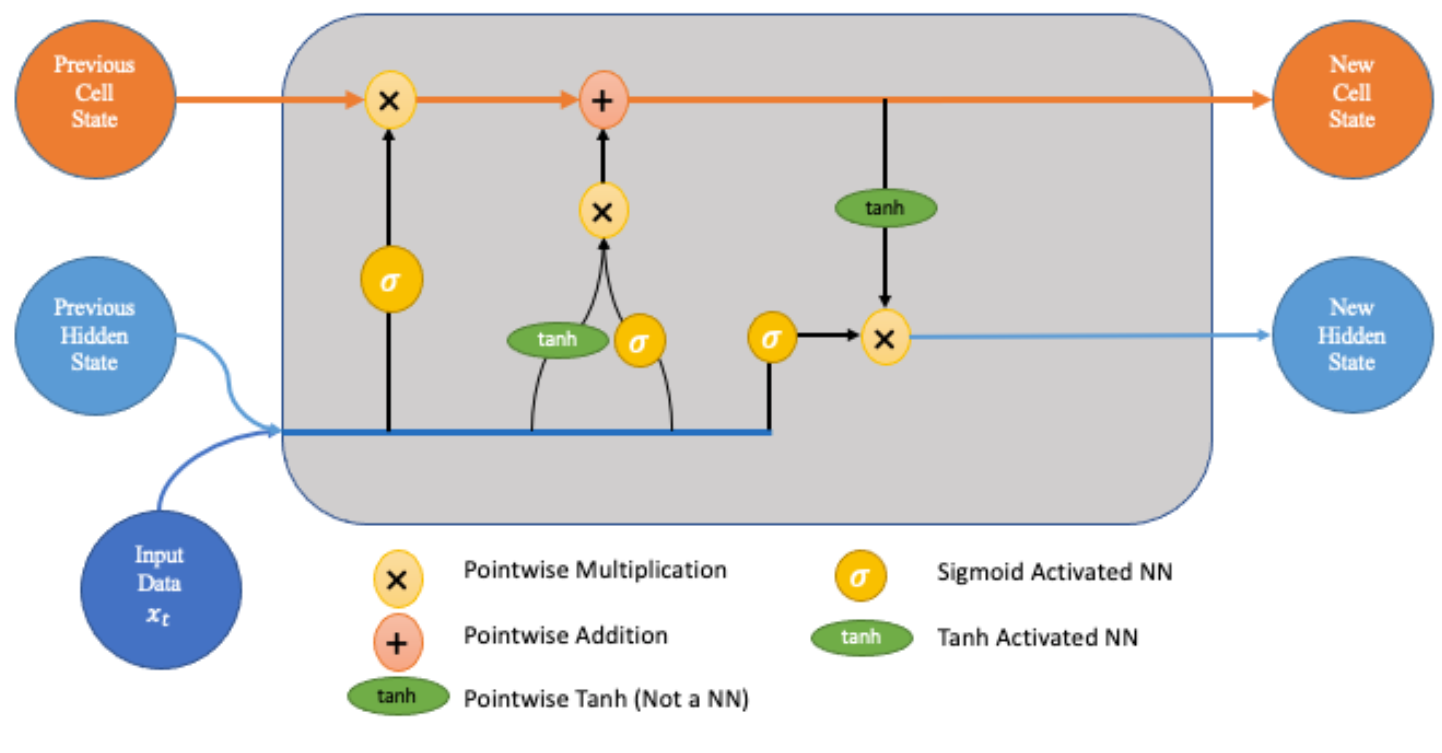
At the core of an LSTM network lies its intricate architecture, which consists of several key components:
1. Long-Term Memory (Cell State)
The long-term memory, also known as the cell state, serves as a conveyor belt that runs through the entire length of the sequence. It allows relevant information to flow across time steps, enabling the network to retain important information over long periods.
2. Short-Term Memory (Hidden State)
The short-term memory, or hidden state, captures the relevant information from the current input and the previous hidden state. It serves as the memory of the network for the current time step and influences the next hidden state and cell state.
3. Forget Gate
The forget gate determines which information from the cell state should be discarded or forgotten. It takes input from the current input and the previous hidden state and outputs a value between 0 and 1 for each element in the cell state. A value of 1 indicates "retain this information," while 0 indicates "forget this information."
4. Input Gate
The input gate regulates the flow of new information into the cell state. It consists of two parts: the input gate itself, which decides which values to update, and the tanh layer, which creates a vector of new candidate values to add to the cell state.
5. Output Gate
The output gate determines which information from the cell state should be exposed to the next hidden state. It selectively outputs parts of the cell state after passing them through a sigmoid activation function and a tanh activation function.
Why Use LSTM Networks?
LSTM networks offer several advantages over traditional RNNs, making them particularly well-suited for tasks involving long sequences and complex dependencies:
- Long-Term Dependency Handling: LSTM networks excel at capturing long-range dependencies in sequential data, making them ideal for tasks such as language modeling, machine translation, and speech recognition.
- Gradient Stability: By introducing explicit memory cells and gating mechanisms, LSTM networks mitigate the vanishing gradient problem commonly encountered in traditional RNNs, allowing for more stable and efficient training.
- Versatility: LSTM networks can be applied to a wide range of sequential data types, including text, audio, video, and time series, making them a versatile choice for various machine learning tasks.
Conclusion
In conclusion, LSTM networks represent a significant advancement in the field of deep learning, enabling the effective processing of sequential data with long-term dependencies. By incorporating memory cells and gating mechanisms, LSTM networks overcome the limitations of traditional RNNs and offer enhanced performance across a variety of tasks. Whether it's natural language processing, speech recognition, or time series analysis, LSTM networks continue to push the boundaries of what's possible in deep learning research and applications.