Transformers: Revolutionizing Society
In the dynamic landscape of deep learning, few innovations have sparked as much excitement and transformation as the advent of transformers. These architectural marvels have redefined the boundaries of natural language processing (NLP) and computer vision (CV), elevating AI capabilities to unprecedented heights. But what makes transformers so remarkable, and why are they at the forefront of modern AI research?
Traditionally, recurrent neural networks (RNNs) and convolutional neural networks (CNNs) held sway over sequential and spatial data, respectively. While effective in many tasks, these architectures struggled with capturing long-range dependencies in sequences, limiting their applicability in complex language understanding and image processing tasks.
Enter transformers, a groundbreaking architecture introduced in the seminal paper "Attention is All You Need" by Vaswani et al. (2017). At its core, transformers leverage the power of attention mechanisms to enable parallel processing of input sequences, effectively overcoming the limitations of sequential processing in RNNs. This parallelization not only accelerates training but also allows transformers to capture intricate patterns and dependencies across long sequences with unparalleled efficiency.
One of the key features that sets transformers apart is their ability to learn contextual representations of words or image patches. Through self-attention mechanisms, transformers can weigh the importance of each element in the input sequence, dynamically adjusting their focus based on context. This mechanism enables transformers to grasp subtle nuances in language and discern intricate visual patterns, leading to state-of-the-art performance across a myriad of NLP and CV tasks.
But perhaps the most astonishing aspect of transformers lies in their versatility. Unlike traditional models, which often require task-specific architectures and fine-tuning, transformers employ a unified architecture that can be seamlessly adapted to various tasks through simple modifications. This inherent flexibility, combined with their superior performance, has positioned transformers as the cornerstone of modern deep learning, capable of tackling diverse challenges ranging from machine translation and sentiment analysis to object detection and image captioning.
Architecture
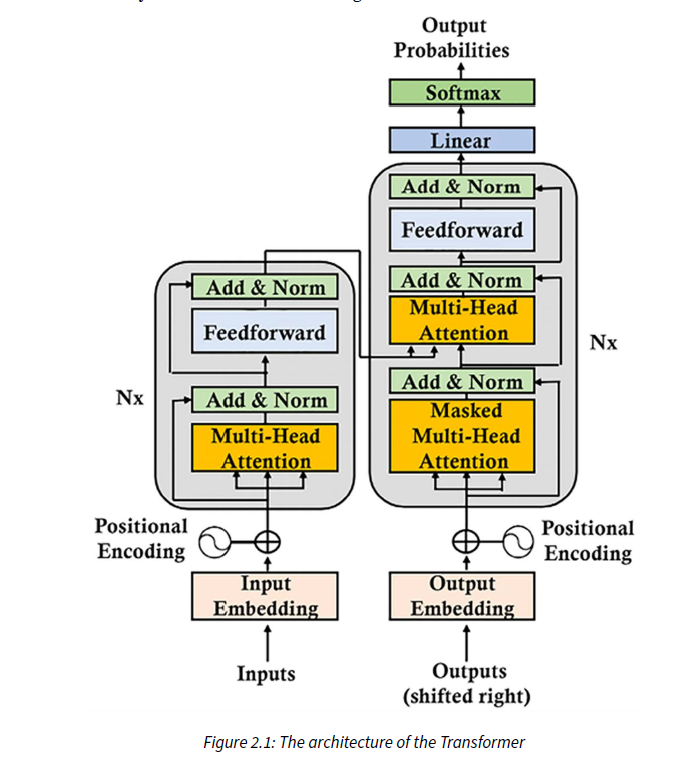
Left ->Encoder
Right->Decoder
Encoder Stack
1. Input: The input to the encoder is a sequence of tokens, typically represented as integers corresponding to words or subwords in the vocabulary.
2. Tokenization: This is the process of breaking down the input text into individual tokens, which could be words, subwords, or characters. Tokenization ensures that each element in the sequence is meaningful and can be processed independently.
3. Word Embeddings: Each token is mapped to a high-dimensional vector representation known as a word embedding. These embeddings capture the semantic meaning of the tokens and help the model understand the context of the input.
4. Positional Embeddings: Since transformers do not inherently understand the sequential order of tokens, positional embeddings are added to the word embeddings to convey the position of each token in the sequence. This allows the model to differentiate between tokens based on their positions.
5. Positional Encoding: Positional encoding is the sum of word embeddings and positional embeddings. It injects positional information into the word embeddings, ensuring that each token representation carries both semantic and positional information.
6. Multihead Attention1. Input: The input to the encoder is a sequence of tokens, typically represented as integers corresponding to words or subwords in the vocabulary.
7. Add and Norm: After multihead attention, residual connections are added, followed by layer normalization. Residual connections help alleviate the vanishing gradient problem, while layer normalization stabilizes the training process by normalizing the activations of each layer.
8. Feedforward Network: Following the add and norm operation, each token representation passes through a feedforward neural network (FNN). The FNN consists of linear transformations followed by non-linear activation functions, allowing the model to capture complex patterns in the data.
9. Add and Norm (again): Similar to after the multihead attention layer, residual connections and layer normalization are applied again after the feedforward network.: This is a key component of the transformer architecture. Multihead attention allows the model to weigh the importance of each token in the context of the entire sequence. It computes attention scores between all pairs of tokens, enabling the model to capture dependencies and relationships between words in parallel.
7. Add and Norm: After multihead attention, residual connections are added, followed by layer normalization. Residual connections help alleviate the vanishing gradient problem, while layer normalization stabilizes the training process by normalizing the activations of each layer.
8. Feedforward Network: Following the add and norm operation, each token representation passes through a feedforward neural network (FNN). The FNN consists of linear transformations followed by non-linear activation functions, allowing the model to capture complex patterns in the data.
9. Add and Norm (again): Similar to after the multihead attention layer, residual connections and layer normalization are applied again after the feedforward network.
Conclusion
In harnessing the power of transformers, we've witnessed a revolution in deep learning, propelled by four key pillars that underpin their remarkable success.
1.Parallel Processing in Attention Layer: The introduction of attention mechanisms has ushered in a new era of parallel processing in sequence modeling. By computing attention scores across all tokens simultaneously, transformers enable efficient and scalable learning, transcending the sequential limitations of traditional recurrent architectures. This parallelism not only accelerates training but also empowers models to capture intricate dependencies across long sequences, unlocking unprecedented performance in NLP and CV tasks.
2.Effective Use of GPU: Transformers leverage the computational prowess of GPUs to unleash their full potential. With their highly parallelizable architecture, transformers exploit the massive parallel processing capabilities of GPUs, enabling rapid training and inference on large-scale datasets. This symbiotic relationship between transformers and GPUs has democratized access to state-of-the-art AI technologies, empowering researchers and practitioners to push the boundaries of innovation across diverse domains.
3.Large Amount of Data: The data hunger of deep learning models finds satiation in the vast reservoirs of data available today. Transformers thrive on large-scale datasets, feasting on the rich tapestry of linguistic and visual information to distill meaningful insights. By ingesting copious amounts of data, transformers learn robust representations that generalize well to unseen tasks and domains, paving the way for transfer learning and pretraining paradigms that fuel advancements in AI research and applications.
4.One Architecture for All: Perhaps the most groundbreaking aspect of transformers is their unified architecture, which serves as a Swiss army knife for diverse tasks in NLP and CV. Unlike traditional models that require bespoke architectures for each task, transformers offer a single, versatile blueprint that can be effortlessly adapted to a myriad of applications with minimal modifications. This universality not only streamlines research and development efforts but also fosters cross-pollination of ideas and techniques across different domains, propelling the march of AI towards ever greater heights of innovation and discovery.
As we reflect on the transformative impact of transformers, it becomes evident that their ascent represents more than just a technological breakthrough—it embodies a paradigm shift in the way we conceptualize and approach deep learning. By embracing parallelism, harnessing computational resources, embracing data abundance, and championing architectural elegance, transformers have emerged as the vanguards of a new era in AI, where the boundaries of possibility are limited only by the bounds of our imagination.