Mixture of Experts: The Power of Specialized Models in Modern AI
Introduction
In the ever-evolving landscape of artificial intelligence and machine learning, one concept that has garnered significant attention is the "Mixture of Experts" (MoE). As the demand for more efficient and accurate models grows, MoE has emerged as a powerful technique to harness the expertise of multiple specialized models, thereby improving performance across a wide range of tasks. This blog explores the fundamental principles behind MoE, its evolution, and how it's being used in contemporary AI systems to achieve state-of-the-art results.
Understanding Mixture of Experts
What is Mixture of Experts?
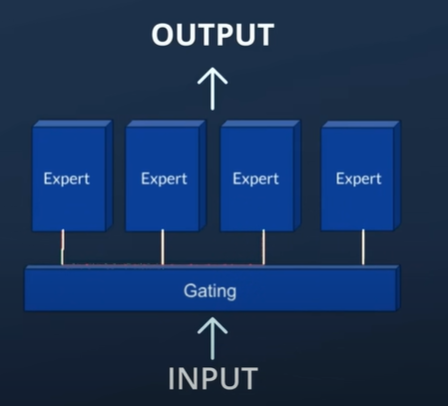
The Mixture of Experts (MoE) is a machine learning paradigm that divides complex problems into simpler sub-problems, each handled by specialized models known as "experts." A gating network decides which experts are best suited to tackle a given input, ensuring that each part of the input is processed by the most appropriate model. This modular approach allows for more efficient and accurate processing, as each expert can focus on a specific aspect of the problem.
Core Components of MoE
- Experts: These are individual models, often neural networks, each trained to specialize in a particular sub-task or data subset. For instance, one expert might excel at recognizing cats in images, while another is adept at detecting dogs.
- Gating Network: This network acts as a mediator, dynamically assigning tasks to the appropriate experts. The gating network typically uses softmax or other probabilistic mechanisms to determine the contribution of each expert to the final output.
- Ensemble Mechanism: The outputs from various experts are combined, often weighted by the gating network’s probabilities, to produce the final prediction. This ensemble approach helps in capturing a wide range of patterns and nuances in the data.
Advantages of Mixture of Experts
- Scalability: MoE scales well to large models and datasets. By assigning specific tasks to different experts, it reduces the overall computational load, making it feasible to train and deploy large-scale models.
- Specialization: Each expert can be trained to specialize in a particular aspect of the problem, leading to more accurate and robust predictions.
- Efficiency: By leveraging the gating network to activate only the relevant experts for each input, MoE models can significantly reduce redundant computations, improving efficiency.
- Flexibility: MoE allows for easy integration of new experts without the need to retrain the entire model, making it highly adaptable to changing requirements and new data.
Evolution of Mixture of Experts
Early Developments
The concept of MoE was introduced in the early 1990s by researchers like Ronald Jacobs, Michael Jordan, and others. Early implementations were primarily used in neural networks to divide complex tasks into manageable sub-tasks. However, the computational limitations of the time restricted its broader application.
Revival in Modern AI
With the advent of deep learning and increased computational power, MoE has experienced a resurgence. Modern implementations, such as Google’s Switch Transformer and Microsoft’s Turing-NLG, have demonstrated the potential of MoE to handle massive datasets and complex tasks with unprecedented efficiency and accuracy.
Modern Implementations of MoE
Google’s Switch Transformer
One of the most notable applications of MoE is Google’s Switch Transformer, which introduces a new architecture that scales efficiently to extremely large models. The Switch Transformer activates only one or a few experts per input, making it highly efficient in terms of computational resources. This selective activation allows the model to process vast amounts of data with fewer parameters, achieving state-of-the-art performance in language modeling and translation tasks.
Microsoft’s Turing-NLG
Microsoft’s Turing Natural Language Generation (Turing-NLG) also leverages MoE to enhance its language generation capabilities. By incorporating multiple experts specializing in different linguistic aspects, Turing-NLG can generate more coherent and contextually relevant text, outperforming previous models on a variety of benchmarks.
OpenAI’s Mixture of Denoisers
OpenAI’s work on generative models has also embraced the MoE framework. In models like DALL-E and CLIP, MoE is used to combine multiple denoisers, each focusing on different aspects of image generation and text-to-image synthesis. This approach enhances the model’s ability to generate high-quality images from textual descriptions.
Challenges and Future Directions
Model Complexity
One of the primary challenges with MoE is managing the complexity of the gating network and the interaction between experts. As the number of experts increases, so does the complexity of coordinating them effectively, which can lead to difficulties in training and optimization.
Resource Allocation
Efficiently allocating computational resources among experts remains a challenge. The gating network must strike a balance between activating sufficient experts to capture the input’s complexity and minimizing redundant computations to preserve efficiency.
Interpretability
Interpreting the decisions of MoE models can be challenging due to the intricate interplay between the gating network and the experts. Developing methods to better understand and visualize the contributions of individual experts is an ongoing area of research.
Future Directions
The future of MoE is promising, with ongoing research focused on improving the scalability, efficiency, and interpretability of these models. Emerging techniques such as meta-learning, neural architecture search, and advancements in hardware acceleration are expected to further enhance the capabilities of MoE, opening up new possibilities for its application in diverse domains ranging from natural language processing to computer vision and beyond.
Conclusion
The Mixture of Experts represents a significant advancement in the field of machine learning, offering a powerful approach to tackling complex tasks with greater efficiency and accuracy. As modern AI systems continue to evolve, the principles of MoE are set to play a crucial role in shaping the future of intelligent systems. By leveraging the strengths of specialized models and dynamically allocating resources, MoE paves the way for more scalable, adaptable, and robust AI solutions.
This blog provides an overview of the Mixture of Experts approach, highlighting its key concepts, advantages, modern implementations, and future prospects. It underscores the importance of MoE in advancing the capabilities of machine learning models and its potential to drive innovation in various fields.
High Level Diagram for the same